|
|
| Line 5: |
Line 5: |
| | ===Updated Closest Zif268 Fingers=== | | ===Updated Closest Zif268 Fingers=== |
| | We realized that some of our "close non-zif268 fingers" were actually not all that close to Zif268, and so we went into the 88,000 zinc finger database and pulled out zinc fingers surrounding zif268. In fact, there were many, many, many zinc fingers that had identical sequences to the Zif268 F2 finger, and so we looked at sequences around it. The tree below shows the new non-zif268 backbones that are actually close to zif268 compared to our old set. The new set is in gray, the old set is in black. This gives us a potential seven more backbones to work with. | | We realized that some of our "close non-zif268 fingers" were actually not all that close to Zif268, and so we went into the 88,000 zinc finger database and pulled out zinc fingers surrounding zif268. In fact, there were many, many, many zinc fingers that had identical sequences to the Zif268 F2 finger, and so we looked at sequences around it. The tree below shows the new non-zif268 backbones that are actually close to zif268 compared to our old set. The new set is in gray, the old set is in black. This gives us a potential seven more backbones to work with. |
| - | [[File:ComparisonTree.png]] | + | [[File:HARVComparisonTree.png]] |
| | ==June 24th - Bioinformatics== | | ==June 24th - Bioinformatics== |
| | | | |
| Line 17: |
Line 17: |
| | | | |
| | {| | | {| |
| - | | [[File:GAA_generated_round_1.png|thumb|left|Round 1 of generating sequences for GAA with the program.]] | + | | [[File:HARVGAA_generated_round_1.png|thumb|left|Round 1 of generating sequences for GAA with the program.]] |
| - | | [[File:GAA_generated_round_2.png|thumb|left|Round 2 of generating sequences for GAA with the program.]] | + | | [[File:HARVGAA_generated_round_2.png|thumb|left|Round 2 of generating sequences for GAA with the program.]] |
| | |- | | |- |
| - | | [[File:GAA_open_and_persikov.png|thumb|left|GAA sequences from the OPEN dataset.]] | + | | [[File:HARVGAA_open_and_persikov.png|thumb|left|GAA sequences from the OPEN dataset.]] |
| - | | [[File:GAA_open_only.png|thumb|left|GAA sequences from Persikov and OPEN datasets.]] | + | | [[File:HARVGAA_open_only.png|thumb|left|GAA sequences from Persikov and OPEN datasets.]] |
| | |} | | |} |
| | | | |
| Line 75: |
Line 75: |
| | | | |
| | {| | | {| |
| - | | [[File:CTC_0.png|thumb|left|psu = 0]] | + | | [[File:HARVCTC_0.png|thumb|left|psu = 0]] |
| - | | [[File:CTC_.005_psuedo.png|thumb|left|psu = .005]] | + | | [[File:HARVCTC_.005_psuedo.png|thumb|left|psu = .005]] |
| - | | [[File:CTC_.008_psuedo.png|thumb|left|psu = .008]] | + | | [[File:HARVCTC_.008_psuedo.png|thumb|left|psu = .008]] |
| | |- | | |- |
| - | | [[File:CTC_.01.png|thumb|left|psu = .01]] | + | | [[File:HARVCTC_.01.png|thumb|left|psu = .01]] |
| - | | [[File:CTC_.015_psuedo.png|thumb|left|psu = .015.]] | + | | [[File:HARVCTC_.015_psuedo.png|thumb|left|psu = .015.]] |
| - | | [[File:CTC_.02_psuedo.png|thumb|left|psu = .020.]] | + | | [[File:HARVCTC_.02_psuedo.png|thumb|left|psu = .020.]] |
| | |} | | |} |
| | | | |
| Line 136: |
Line 136: |
| | *Run on E Gel to check PCR worked: bands are at the same sizes as the original genotyping gel. | | *Run on E Gel to check PCR worked: bands are at the same sizes as the original genotyping gel. |
| | | | |
| - | [[File:2011.06.27.pyrFrpoZloci2(labeled)|thumb|none|PCR of kan-ZFB-wp-his3-ura3]] | + | [[File:HARV2011.06.27.pyrFrpoZloci2(labeled)|thumb|none|PCR of kan-ZFB-wp-his3-ura3]] |
| | | | |
| | *Tomorrow we will send samples to Genewiz for sequencing | | *Tomorrow we will send samples to Genewiz for sequencing |
| Line 216: |
Line 216: |
| | | | |
| | *E gel to check reactions worked: all 6 overlap PCRs successful, but not the other two reactions. | | *E gel to check reactions worked: all 6 overlap PCRs successful, but not the other two reactions. |
| - | [[File:2011.06.28kanZFBconstruct(labeled).png|thumb|none|kan-ZFB-wp-hisura construct 6/28/11]] | + | [[File:HARV2011.06.28kanZFBconstruct(labeled).png|thumb|none|kan-ZFB-wp-hisura construct 6/28/11]] |
| | | | |
| | *combined samples 1-3 and 4-6 and ran on 1% agarose gel for extraction | | *combined samples 1-3 and 4-6 and ran on 1% agarose gel for extraction |
| - | [[File:2011.06.28kanZFBconstruct_for_extract1(labeled).png|thumb|none|kan-ZFB-wp-hisura construct for gel extraction 6/28/11]] | + | [[File:HARV2011.06.28kanZFBconstruct_for_extract1(labeled).png|thumb|none|kan-ZFB-wp-hisura construct for gel extraction 6/28/11]] |
| | | | |
| | *used Qiagen gel extraction kit and instructions with the following modifications: | | *used Qiagen gel extraction kit and instructions with the following modifications: |
| Line 249: |
Line 249: |
| | ===Plasmid and Oligo Design Schematics=== | | ===Plasmid and Oligo Design Schematics=== |
| | {| | | {| |
| - | | [[File:Oligo design on board.jpg|thumb|left|Oligo Design]] | + | | [[File:HARVOligo design on board.jpg|thumb|left|Oligo Design]] |
| - | | [[File:Plasmid design on board.jpg|thumb|left|Expression Plasmid Design]] | + | | [[File:HARVPlasmid design on board.jpg|thumb|left|Expression Plasmid Design]] |
| | |} | | |} |
| | | | |
| | ===Chip-Based Sequence Design Schematic=== | | ===Chip-Based Sequence Design Schematic=== |
| | {| | | {| |
| - | |[[File:Chip_protocol.png|thumb|left|Chip-based process for sequence design, taken from Kosuri, et al. 2010 model of scalable gene synthesis <cite>Kosuri2010</cite>]] | + | |[[File:HARVChip_protocol.png|thumb|left|Chip-based process for sequence design, taken from Kosuri, et al. 2010 model of scalable gene synthesis <cite>Kosuri2010</cite>]] |
| | |} | | |} |
| | ====References==== | | ====References==== |
| Line 265: |
Line 265: |
| | | | |
| | {| | | {| |
| - | | [[File:Harvard_logo.png|thumb|left|]] | + | | [[File:HARVHarvard_logo.png|thumb|left|]] |
| | |} | | |} |
| | | | |
| | | | |
| | ===Running the Generator!=== | | ===Running the Generator!=== |
| - | [[File:Fasta_total.csv]] NOTE: LATER GENERATED NEW SEQUENCES. NOT UP TO DATE. | + | [[File:HARVFasta_total.csv]] NOTE: LATER GENERATED NEW SEQUENCES. NOT UP TO DATE. |
| | ====Generated Final Chip Sequences==== | | ====Generated Final Chip Sequences==== |
| | *We ran the generator once earlier this afternoon, but had to re-run it again due to a typo in the cut sites and the number of sequences we desired for each backbone. Luckily, we caught these errors, and after checking the program once again, we ran it a final time this afternoon. | | *We ran the generator once earlier this afternoon, but had to re-run it again due to a typo in the cut sites and the number of sequences we desired for each backbone. Luckily, we caught these errors, and after checking the program once again, we ran it a final time this afternoon. |
| Line 287: |
Line 287: |
| | ====Generated WebLogos for Final Chip==== | | ====Generated WebLogos for Final Chip==== |
| | {| | | {| |
| - | | [[File:AAA.png|thumb|left|AAA]] | + | | [[File:HARVAAA.png|thumb|left|AAA]] |
| - | | [[File:ACC.png|thumb|left|ACC]] | + | | [[File:HARVACC.png|thumb|left|ACC]] |
| - | | [[File:CTC.png|thumb|left|CTC]] | + | | [[File:HARVCTC.png|thumb|left|CTC]] |
| | |- | | |- |
| - | | [[File:CTG.png|thumb|left|CTG]] | + | | [[File:HARVCTG.png|thumb|left|CTG]] |
| - | | [[File:GAC.png|thumb|left|GAC]] | + | | [[File:HARVGAC.png|thumb|left|GAC]] |
| - | | [[File:TGG.png|thumb|left|TGG]] | + | | [[File:HARVTGG.png|thumb|left|TGG]] |
| | |} | | |} |
| | | | |
| Line 303: |
Line 303: |
| | ===Bioinformatics Candids=== | | ===Bioinformatics Candids=== |
| | {| | | {| |
| - | | [[File:Justin speaking.jpg|thumb|left]] | + | | [[File:HARVJustin speaking.jpg|thumb|left]] |
| - | | [[File:Justin writing.jpg|thumb|left]] | + | | [[File:HARVJustin writing.jpg|thumb|left]] |
| - | | [[File:Zif268 sequence by memory.jpg|thumb|left|zif268 sequence by memory. You know you've stared at too many zif268 sequences when...]] | + | | [[File:HARVZif268 sequence by memory.jpg|thumb|left|zif268 sequence by memory. You know you've stared at too many zif268 sequences when...]] |
| | |} | | |} |
| | | | |
| | | | |
| - | [[File:Primer Index_iGEM 2011]] | + | [[File:HARVPrimer Index_iGEM 2011]] |
| | | | |
| | ===Design of Plate Practice Sequences=== | | ===Design of Plate Practice Sequences=== |
| Line 366: |
Line 366: |
| | **E Gel of product: both wild-type and the sample hopefully containing the insert had the same short band of around 350bp--the recombination was unsuccessful | | **E Gel of product: both wild-type and the sample hopefully containing the insert had the same short band of around 350bp--the recombination was unsuccessful |
| | | | |
| - | [[File:1529620locus(labeled).png|thumb|none|kan-ZFB insertion into the 1529620 locus 6/29/11]] | + | [[File:HARV1529620locus(labeled).png|thumb|none|kan-ZFB insertion into the 1529620 locus 6/29/11]] |
| | | | |
| | *Used overnight saturated culture to reinoculate; once close to mid-log, culture split into 2 1.5mL amounts and 37.5µL arabinose added to each | | *Used overnight saturated culture to reinoculate; once close to mid-log, culture split into 2 1.5mL amounts and 37.5µL arabinose added to each |
| Line 439: |
Line 439: |
| | **Therefore we sent the PCR products and primers to GENEWIZ for sequencing again | | **Therefore we sent the PCR products and primers to GENEWIZ for sequencing again |
| | | | |
| - | [[File: 2011.06.30.lambda_spec_pyrFrpoZ(labeled).png|thumb|none|pKD46, pZE21G, and PyrF and rpoZ loci 6/30/11]] | + | [[File:HARV2011.06.30.lambda_spec_pyrFrpoZ(labeled).png|thumb|none|pKD46, pZE21G, and PyrF and rpoZ loci 6/30/11]] |
| | | | |
| | '''pZE21G backbone:''' | | '''pZE21G backbone:''' |
June 24
- Designed primer for testing HisB deletion, reuse His_Internal_R to test the band
Updated Closest Zif268 Fingers
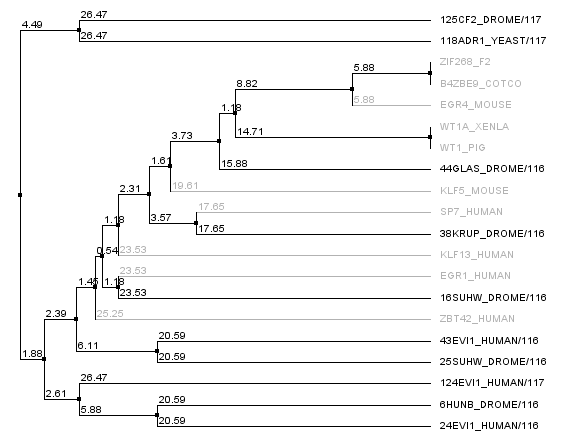
We realized that some of our "close non-zif268 fingers" were actually not all that close to Zif268, and so we went into the 88,000 zinc finger database and pulled out zinc fingers surrounding zif268. In fact, there were many, many, many zinc fingers that had identical sequences to the Zif268 F2 finger, and so we looked at sequences around it. The tree below shows the new non-zif268 backbones that are actually close to zif268 compared to our old set. The new set is in gray, the old set is in black. This gives us a potential seven more backbones to work with.
June 24th - Bioinformatics
Sequence Generation
We made some small updates to the sequence generator, based on the frequencies we noticed in the outputs of the tests we ran.
- We decided to only include pseudocounts for position 6 for 'CNN' and 'ANN.' Originally, 'CNN' and 'ANN' were using pseudocounts for all seven positions. However, this introduced a noticeable increase in amino acids, such as tyrosine (Y), that have been shown to occur rarely in zinc fingers (according to our data from OPEN and Persikov). Additionally, because tryosines occured so rarely in the data (11 times total in the open data set), we decided not to give tyrosine a pseudocount.
- We added the capability to prevent repeat backbone-helix combinations on the chip. That is, we wanted to make sure that the same exact zinc finger was not generated for different triplet inputs.
To test the sequence generator, we made two sets of 2000 sequences for GAA, then infographic-d the results. Comparing these with the images for OPEN and OPEN+Persikov shows that our generation follows the major themes of those datasets, but also introduces variation. The two generated sets also vary slightly from each other, which shows the influence of randomness on the generation.
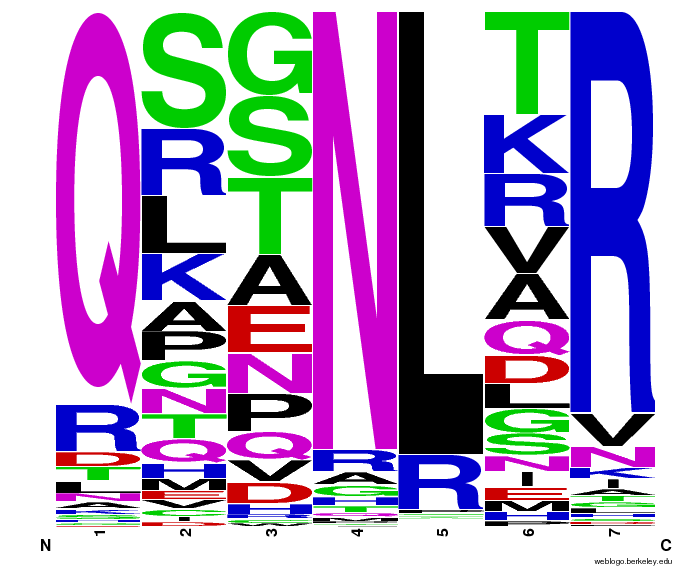 Round 1 of generating sequences for GAA with the program. |  Round 2 of generating sequences for GAA with the program. |
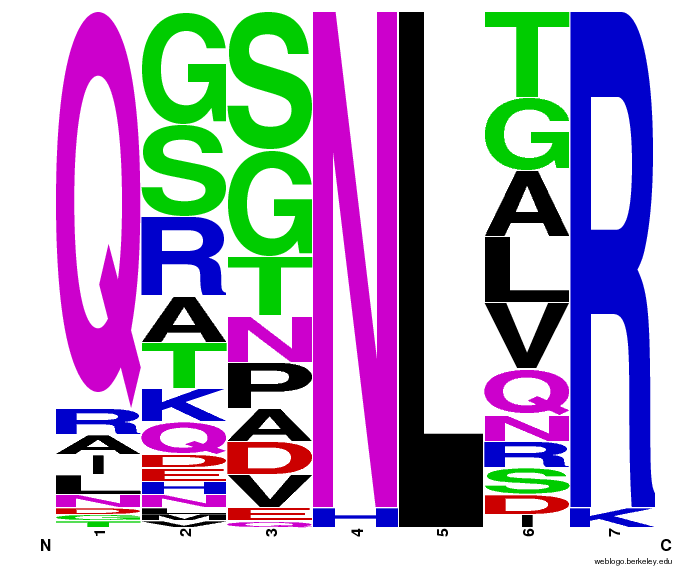 GAA sequences from the OPEN dataset. |  GAA sequences from Persikov and OPEN datasets. |
| Disease
| Target DNA Finger 1
| Helices in Zif268 Backbone
| Helices in Zif268 Closely-Related Backbones
| Helices in Zif268 Distantly-Related Backbones
|
| Colorblindness (Bottom) | TGG | 5150 | 3000 | 1000
|
| Colorblindness (Top) | ATG | 3050 | 3050 | 3050
|
| Familial Hypercholesterolemia (Bottom) | GAC | 5150 | 3000 | 1000
|
| Familial Hypercholesterolemia (Top) | CTG | 3050 | 3050 | 3050
|
| Myc (Top198) | CTC | 3050 | 3050 | 3050
|
| Myc (Top981) | AAA | 3050 | 3050 | 3050
|
Table of target sequences and helix distribution across backbones
- Distribution: Zif268 : Zif268 similar : Zif 268 dissimilar
- Conservative distribution 56.3 : 32.8 : 10.9
- Riskier distribution 33.3 : 33.3 : 33.3
June 24th
pZE21G:
- reinoculated culture with 100µL of saturated solution, grew to mid-log, and made glycerol stock
- backbone PCR: ran E gel but no bands--PCR unsuccessful. We may need to use a different backbone for the zinc fingers.
Omega and Omega+Zif268:
- these were the only two PCR reactions from 6/22/11 to work
- PCR purified using Qiagen kit:
- omega: 6.1ng/µL, 260/280=1.83
- omega+Zif268: 11.3 ng/µL, 260/280=1.67
Lambda red recombination of selection system:
- reinoculated selection strain+pKD46 with 100µL of saturated solution
- just before mid-log (about 4 hours after inoculation) divided culture in half (1.5mL) and added either 37.5µL or 3.75µL of 20% arabinose solution (to try two different induction levels). Cultures grew for another hour.
- The rest of the procedure was the same as the 6/22/11 attempt but without the 42C water bath.
June 24th - Bioinformatics
Playing with Pseudocounts
Using CTC because of position 6's reliance on the CNN frequencies, we see what difference values of pseudocounts (if in the frequency table, the frequency of an amino acid is 0, bump it up to the psuedocount: ex. A = 0 becomes A = .015 with a psuedocount of .015) make. Pseudocounts are necessary for data that has small sample size - we could be missing out on working helices because a letter's frequency is 0 when it shouldn't be.
Various pseudocount (psu = ) values. Look at the 7th column, which is position 6 in the helix:
The variation from E being the top letter to A being top back to E is from a slight adjustment in how we add on psuedocounts: the 'new' way is a more proportional approach.
Notice how psu = 0 gives only the four letters found in our dataset, while psu > 0 adds in other letters, each with a small probability ranging from .5% to 2%.
The question is how much psu to add: less means we weight our (possibly flawed) data of proven zinc fingers more. Higher psu adds more randomness (variation) to our sequences, but some fraction of those sequences will not work.
List of Remaining Goals:
- Sort fingers by target
- Pick and assign primer sets
- Reverse translate fingers avoiding type II restriction enzymes and primers
- Append type II restriction enzyme and primer sequences to each finger
- Yay
June 28th
Sequencing:
- the following samples from 6/27 were sent to Genewiz for sequencing:
- PyrF F, R (one sample with PyrF_F, one with PyrF_R)
- rpoz F, R (one sample with rpoz_F, one with rpoz_R)
Lambda red results:
- the colonies on the plates did not look promising, and the ones we chose and grew up in LB+kan did not actually grow. Just to be certain, we choose 18 more colonies: 6 from 37.5µL arabinose 100µL plated, 6 from 3.75µL arabinose 100µL plated, and 6 from 37.5µL arabinose 1.5mL plated. Three from each plate were grown in plain LB and three with kan. We will let it grow in 30˚C, overnight if necessary, and hopefully see bacteria for PCR.
- Assuming this does not work, we prepared more ∆HisB∆PyrF∆rpoZ+pKD46 in two ways: we put 3 colonies in LB+amp from the 6/16 transformation plate, and we streaked a new amp plate from the glycerol stock
- Another possibility is that something is wrong with our lambda red. We designed primers to verify that the pKD46 plasmid is really in the cells.
Kan-ZFB-wp-his3-ura3 construct:
- Our last few PCR purifications have given us very low yields, and consequently we have had to use large amounts of our DNA (and the large amounts of buffer salts may also be why our lambda red recombinations have failed). When we tried to amplify our current DNA using the hisura-kan_F and ZFB-wp-hisura_R primers and the Phusion mastermix, it did not work (see 6/23). We will try to gain more product in two ways:
1) Repeat 6/23 PCR but use KAPA mastermix
- the KAPA mix may work better than the Phusion.
- Used KAPA protocol with 1µL of kan-ZFB overlap as template, hisura-kan_F and ZFB-wp-hisura_R primers, 65˚C annealing temp, 90 sec elongation time
- made 2 reactions
2) Repeat overlap extension PCR (see 6/16) with KAPA mastermix
- used KAPA protocol with 1µL kan cassette and 1µL of ZFB-wp-hisura, 65˚C annealing temp, 90 sec elongation
- 10 cycles without primers; hisura-kan_F and ZFB-wp-hisura_R primers added; 15 more cycles
- made 6 reactions
- E gel to check reactions worked: all 6 overlap PCRs successful, but not the other two reactions.
kan-ZFB-wp-hisura construct 6/28/11
- combined samples 1-3 and 4-6 and ran on 1% agarose gel for extraction
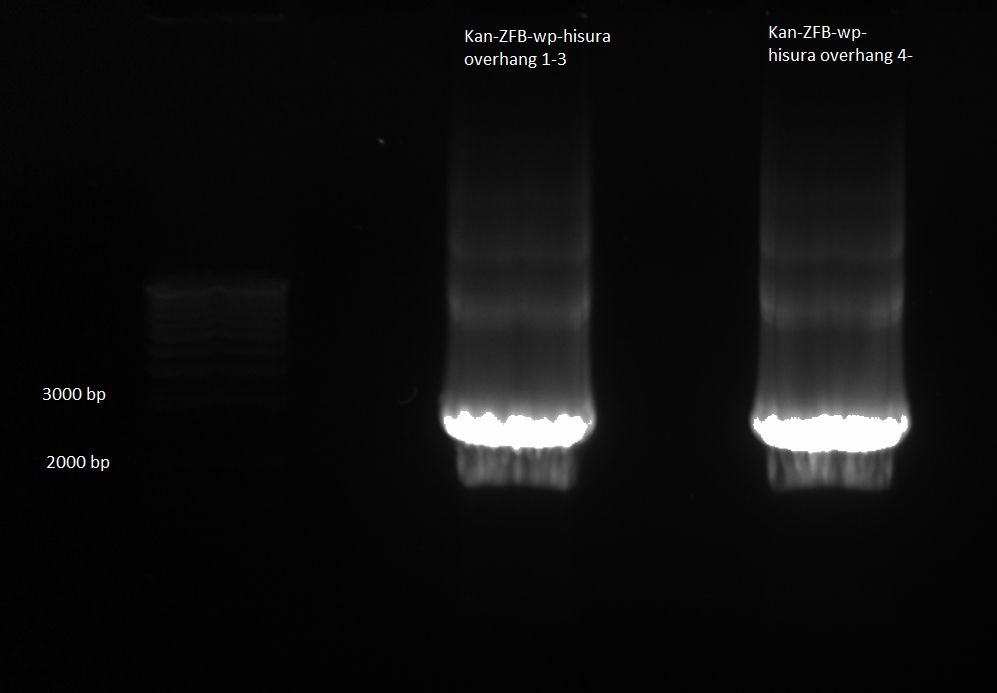
kan-ZFB-wp-hisura construct for gel extraction 6/28/11
- used Qiagen gel extraction kit and instructions with the following modifications:
- gel bands were dissolved in 500µL of buffer QG regardless of the gel volume
- gel heated at 50C for 20 min (to make up for reduced amount of buffer QG)
- after melting, 10µL of NaOAC (3M) were added to adjust the pH
- DNA from samples 1-3 were eluted in 20µL of ddH2O; DNA from samples 4-6 were eluted in 20µL of buffer EB
- water sample: 273.4 ng/µL, 260/280=1.92
- EB sample: 136.9 ng/µL, 260/280=2.38
June 28th - Bioinformatics
Attention all Harvard iGEM-ers!!! According to the iGEM Main Page, our preliminary project descriptions and safety proposals are due on July 15. Please see the aforementioned link so we can get this done ASAP- we don't want to miss any deadlines and have all our hard work wasted!
- Length of chip oligos: 131-140bp (based on Cut Site Design)
- Primers: 20bp (x2= 40bp)
- zif268 F2 backbone + helix= 23aa (x3=69bp; some fingers ~3aa longer)
- Some alternate backbones are longer than zif268 F2 backbone
- Type II binding/cut sites= 11bp on each side (22bp total)
- Standard legnth: 40 + 69 + 22 = 131bp
- Use WebLogos as a final visual check of our final generated sequences
Plasmid and Oligo Design Schematics
|
| 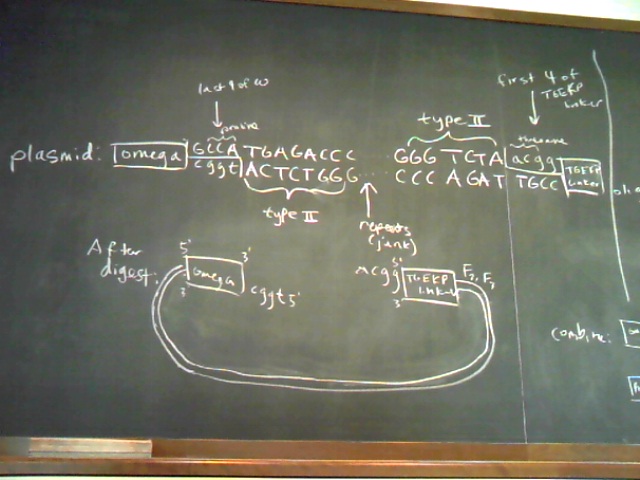 Expression Plasmid Design |
Chip-Based Sequence Design Schematic
 Chip-based process for sequence design, taken from Kosuri, et al. 2010 model of scalable gene synthesis Kosuri2010 |
References
<biblio>
- Kosuri2010 pmid=21113165
</biblio>
Harvard Logo
Running the Generator!
File:HARVFasta total.csv NOTE: LATER GENERATED NEW SEQUENCES. NOT UP TO DATE.
Generated Final Chip Sequences
- We ran the generator once earlier this afternoon, but had to re-run it again due to a typo in the cut sites and the number of sequences we desired for each backbone. Luckily, we caught these errors, and after checking the program once again, we ran it a final time this afternoon.
- It took about 45 minutes for the program to generate and reverse translate the 54900 sequences.
- During this time, we created a function that will re-translate the sequences that the generator output. It compares the original helix with the re-translated helix to make sure that our reverse-translate works properly.
- This step went smoothly, and we verified that the sequences were reverse-translated properly.
- To make sure that the distributions generated were as expected, we made WebLogos of the helices generated(see below).
- The output file (in the Dropbox: iGem > chip > final chip.csv) originally had the following headers: 'Target', 'Backbone #', 'Helix Sequence', 'Backbone Sequence', 'Nucleotide Sequence of Zinc Finger'
- We wanted to convert this information into FASTA format.
- We wrote a function that converted our original file into fasta format (in the Dropbox: iGem > chip > fasta.csv)
- The file FASTA_total (also linked above) contains the FASTA for all 50000 sequences (including the 100 controls).
- For those curious, the FASTA format just a format that looks like this:
>Header (For us the header is: Target, Backbone #, Helix Sequence, Backbone Sequence)(The header for the controls are: Index Number, 'control')
Sequence (In our case, the nucleotide sequence of the zinc fingers)
Generated WebLogos for Final Chip
- FASTA-Formatted Chip Data:
- >NNN(Target Triplet) BB# Helix Seq.
- Nucleotide seq. of ZF
Bioinformatics Candids
|
|
|  zif268 sequence by memory. You know you've stared at too many zif268 sequences when... |
File:HARVPrimer Index iGEM 2011
Design of Plate Practice Sequences
While we wait for the chip to come in, we have a number of techniques and protocols that we can practice on beforehand, so that when the chip comes we'll be ready to go to use what they give us. We will be practicing the following techniques:
- Cutting ZF1 out of our oligos
- Inserting ZF1 into the expression plasmid in between the omega subunit and the linker before F2
- Verifying that combination of our F1 from the oligo with the plasmid produces a viable, functional ZF
- Amplifying subpools of oligos for testing
- Inserting the expression plasmids into the E. coli containing our selection genome
- Verifying that our ZF-binding site/GFP expression paradigm works
To this end, we will be ordering a 96-well plate from IDT containing oligos that will simulate the entire tube of oligos that we will receive from Agilent in four weeks. These oligos will consist of the following:
- 6 positive controls (we know which DNA sequences these bind to)
- 3 of them being the F1 fingers of Zif268, OZ052, and OZ123
- 3 of them being ZF F1s derived from CODA.
- 90 generated sequences, picked from a subset of the chip
- These are picked evenly across the 9,150 sequences generated on the cihp for the TGG triplet F1 target from the colorblindness "bottom finger" target, GTG GGA TGG. This particular target was chosen because the F2/F1 is a GNNTNN combo, which might be more likely to get hits from our chip generation sequences.
The primer tag sequences for the 90 generated sequence subset will be the same as they are on the chip (for the sake of explanation, we will refer to them now as P1F and P1R in this paragraph). The positive controls will be flanked immediately by the same primers as the generated subset so that we can amplify everything as one pool altogether should we need to (so this will be P1F and P1R). However, we will also put an additional set of primers outside of the P1F/P1R primers for the positive controls so that we can specifically amplify the positive control subpool, should we want to. These primers will be the same as the primers for the positive control on the chip (which will be called P2F and P2R here).
To recap, on the chip we will have the following oligos :
45750 other oligos for the 5 other target sequences
Oligos (TGG set, 9150 total): | P1F | type II binding site | generated F1 | type II binding site | P1R |
Oligos (+ control, 100 total): | P2F | type II binding site | control F1 | type II binding site | P2R |
In our test pool of 96 sequences, we will have two types of oligos (note the two pairs of primers around the positive controls):
Oligo (TGG set, 90 total): | P1F | type II binding site | generated F1 | type II binding site | P1R |
Oligo (+ control, 6 total): | P2F | P1F | type II binding site | generated F1 | type II binding site | P1R | P2R |
Once we get our test sequences back from IDT, they will come in a 96-well plate with one oligo in each plate. We should make a mixture using some of each well in order to create a tube that contains all 96 sequences. This will simulate the tube that we will receive from Agilent, except instead of 55,000 sequences we will have 96 sequences only in this tube. From here, we can practice using this as a library.
We can pretend that this tube is just 96 generated sequences on the chip, treating the positive controls as if they were also generated sequences (we only include them in the 96 to ensure that we will indeed get a "hit" from this practice screening). Thus, we can just use the P1F/P1R primer set to amplify all of them in order to use them for the subsequent steps.
These subsequent steps will be those that were outlined above, namely cutting out the F1 sequence from each oligo, ligating this F1 into our expression plasmid, putting the expression plasmid into our selection strain, observing colonies which get infused with ZFs that bind to our target site (the "hits"), and sequencing the colonies that get hits to determine which ZF they are expressing.
We will be repeating these exact same steps once we get the chip, so if we can perfect our protocols with these practice sequences, we should be golden when the chip comes in.
June 30th
Lambda Red, Backbone, and Sequencing PCR
- Gel run on the presence of a Lambda Red protein in the pKD46 plasmid showed that it is indeed present, so our recombination failures have not been due to an incorrect plasmid.
- Gel run on the backbone of pZE21G plasmid was success and took us one step closer to obtaining all parts necessary for the three part assembly
- Gel run on the pyrF and rpoZ was success
- Therefore we sent the PCR products and primers to GENEWIZ for sequencing again

pKD46, pZE21G, and PyrF and rpoZ loci 6/30/11
pZE21G backbone:
- Since last night's PCR was successful, we will redo it with a few protocol adaptations to get a cleaner product and to increase our yield when we purify
- KAPA mastermix and protocol: primers HindIII-F and KpnI-R
- template: pZE21G miniprepped plasmid, 1µL
- 2 min elongation time, 30 cycles
- 2 samples at 55˚C annealing, 2 samples at 60˚C
Lambda red and MAGE:
- Yesterday's prep produced tiny colonies on the MAGE plates and (so far) none on the kan-ZFB plates. Just in case it didn't work, we will redo the lambda red using even more DNA and perform a second round of MAGE using culture from yesterday that was not plated.
- same procedure, but with the following changes:
- 5µL kan-ZFB (about 1 mg)
- recover 3 hrs
- kan-ZFB: plate 100µL and 2 mL on kan plates
- MAGE: plate 1µL and 10µL on amp plates
- To see if the colonies on the MAGE plate knocked out HisB, we chose 24 colonies, resuspended them in water, and put half the cells in LB (complete media) and half in NM media (does not have histidine). 96 well plate, 150µL media, grown overnight at 30˚C.
ZF Expression Plasmid Ultramer and Primer Design
Today, we designed primers ZF_073 through ZF_085 as listed in the iGEM Primer Index spreadsheet. These were basically two sets of primers: the primers to clone out the omega subunit and linker, and the ultramers that would construct the last part of the linker along with the type II binding sites and F2/F3 fingers. One should refer to the primer list for the sequences.
Note: the annealing sequence for the ultramer overlap contained a 72 degree melting temp hairpin. To get around this, I changed one of the codons in the F2 backbone. The F2 backbone begins with "FQCRIC", and so I changed the codon for the arginine (R) from CGC to CGT, which resolved the hairpin problem.
June 30th - Bioinformatics
Updated Primer list and FASTA formatting
We ran into a small hiccup, when we were informed that we had forgotten to reverse translate the reverse primer sequences that were being appended to the generated sequence. This is because the primer sequences we were given were the sequences for the actual primers, rather than sequences to which the primers would bind. Luckily, we caught this error! We did have the re-run the generator because we had to make sure that our generated sequences did not contain the new primers.
- Here is the updated primer list:
This is the set of final target sequences with assigned forward and reverse primers (tags for PCR):
| Disease
| Target Sequence
| Forward Primer (5'-3' NOT REVERSE COMPLEMENT)
| Reverse Primer (5'-3' REVERSE COMPLEMENT)
|
| Colorblindness | GCT GGC TGG | ATATAGATGCCGTCCTAGCG | TGGGCACAGGAAAGATACTT
|
| Colorblindness | GCG GTA ACC | CCCTTTAATCAGATGCGTCG | GGTCGCCCTTATTACTACCA
|
| Familial Hypercholesterolemia | GGC TGA GAC | TTGGTCATGTGCTTTTCGTT | TCTGAGTATCCGATACCCCT
|
| Familial Hypercholesterolemia | GGA GTC CTG | GGGTGGGTAAATGGTAATGC | GCTATATCCGGGGAATCGAT
|
| Myc-gene Cancer | GGC TGA CTC | TCCGACGGGGAGTATATACT | TTGGCCTGAAGCAGTTAGTA
|
| Myc-gene Cancer | GGC TGG AAA | CATGTTTAGGAACGCTACCG | GGGAGGGAACGGAGATTATT
|
| Controls | n/a | GTACATGAAACGATGGACGG | CGCTGAGGAGACTATACCAG
|
There was also a small error in the FASTA formatting. There are not supposed to be any spaces in the header, so the spaces were replaced with underscores.
>1_control
GTACATGAAACGATGGACGGGGTCTCAGCCATTCCAATGTCGTATCTGTATGCGTAATTTTTCACGCAAACACCATTTGGGTCGTCATATCCGTACGCACACGGTGAGACCCGCTGAGGAGACTATACCAG
 "
"











.png)
.png)












.png)
.png)