"
"
Team:METU-BIN Ankara/Project
From 2011.igem.org
METU-BIN iGEM Software TeamProject: Mining for BioBricks
Project
Introduction
While the interest to the field of synthetic biology is uprising, iGEM and Parts Registry is getting more important for researchers interested working in the field of synthetic biology. As the number of attendees and teams to iGEM competition increases each year, number of BioBricks submitted to the Parts Registry are increasing too. As we all know, Parts Registry is an inimitable library for synthetic biologists. Although it is an important source of information and tool for biologists, the parts are not organized very well. Therefore, while constructing devices, synthetic biologists usually faces following difficulties at the pre-experimental stage:
- Searching through the Parts
- Deciding if the parts needed are already in the database or not
- Deciding which BioBrick will work effectively with which
- Finding the most accurate combination between the parts
- Constructing the most effectively working devices
Figuring out all these answers is time consuming and takes too much effort. Our main goal as 2011 METU-BIN iGEM Software team was to provide a web based tool that helps synthetic biologists at the pre-experimental step to search the Part Registry with input and output keywords and to design their genetic constructs using the biobricks provided in the 2011 distribution of DNA constructs.
M4B: Mining for Biobricks is developed to aid synthetic biologist. Our software proposes a method which can be utilized in pre-experimental step as a supporter data mining tool. Following the user defined input and output parameters, M4B lists all possible composite devices and ranks them according to the novel scoring matrix developed by METU-BIN.
Aim
Main goal of our 2011 project is to provide a web based tool that helps synthetic biologists at the pre-experimental step to design their genetic constructs according to their input and output parameters.
- A network of all bioparts in 2011 distribution will be generated, which describes the functional relations between the subatomic bioparts.
- A search algorithm will be developed to reveal all possible device combinations for the user defined input and output within bioparts of 2011 distribution.
- Visualization tools will be applied for graphical representation of the results.
- A web-based user interface will be provided for the developed software.
Algorithm
Extraction of Relations of Bioparts and Construction of Relational Database
Parts Registry contains various types of biobricks and connections in between parts. In our software, we aimed to develop an algorithm which goes over the devices and finds connections between biobricks to present users all possible constructed devices. However, it was very difficult to go over biobricks and find the relations in not very well organized Parts Registry. For that reason, we have decided to form a ”Part Connections Database” by examining all the bilateral relations between biobricks which will be used by our program, M4B. By this way, the complex information in Parts Registry will be simplified and our algorithm will work faster and more effectively.
The biology group focused on all of the four 384 well plates of 2011 distribution and extracted information between connections and devices in a standard way. This information is stored into a relational database and enables queries from remote computer programs.
Our software group developed a toolbox to help biology group in storing the part relations into the new database of connections between biobricks. Using this tool, we were able to minimize the possibility of mistakes while entering bilateral relations manually. More importantly, this organized the database entries in a standardized way, according to the requirements of Mining for BioBricks to run the searching algorithm easily.
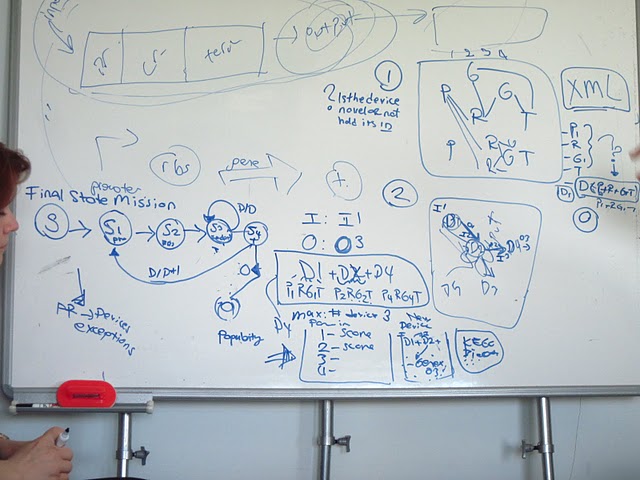
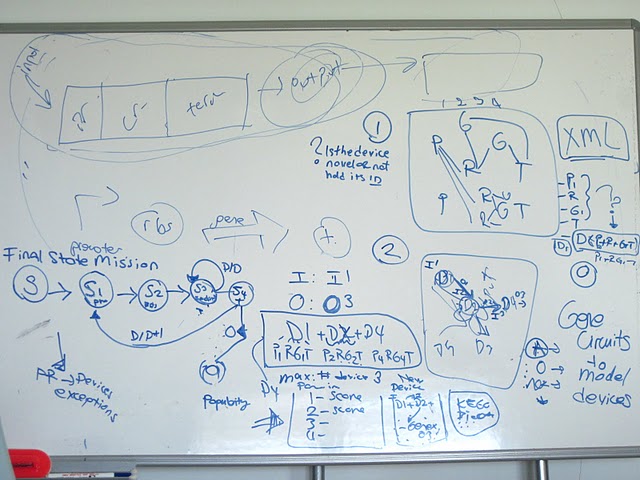
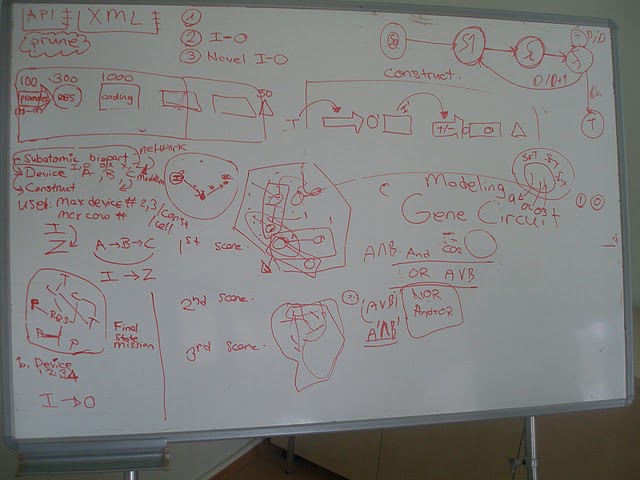
Figure 1: The toolbox which was used while building the “Part Connections Database” by our biology group. Figure 2: A screen shot from our “relational database”As there are various types of biobricks in the Parts Registry, we set up rules to organize the “relational database” in an appropriate way.
Rules
The most important rule is “A constructed device formed by combination of promoter-ribosome binding site-gene-terminator, respectively, is the minimal functional device.”
This is the major rule, because without these 4 major biobrick types, a device cannot work. In addition to this, without knowing the description of “basic device” it is impossible for us to present accurate results to users. Although Parts Registry contains various types of biobricks, in our database there are 4 basic biobricks which are promoters, ribosome binding sites, genes, and terminators. This helped us to simplify the complex information in the Parts Registry in our initial attempt of mining.
In addition to 4 basic biobrick types, there are inputs and outputs which are our software’s parameters. Inputs are chosen according to promoters. Both activators and inhibitors of promoters were listed in our database. Main source of activators and inhibitors was the information from the Parts Registry. The reason of listing inhibitors was to filter out constructed devices which do not produce the required outputs. When a constructed device is formed by multiple devices, although the input activates first device’s promoter, it may inhibit other promoters of following devices. Outputs were chosen according to the genes, the product they synthesize. Although, most of the time, input and output information was extracted from Parts Registry, sometimes external sources were used as well because of the uninformative part descriptions at Parts Registry. External sources such as NCBI, PubMed and wiki of the team who submitted the biobrick to iGEM were used.
Constitutive promoters are entered without any input, but especially their “constitutiveness” is recorded as a property in our relations database.
In our software, after constructing a device by combining biobricks to construct multiple devices, combination between devices is formed according to this rule: “Output of the first gene will be the input of the following promoter(s)”
According to this rule, first promoter will be activated by given Input and the product of first gene will be used as activator of the following promoters. By activation of the promoters, genes will synthesize the output. By this way, the constructed complex is expected to work effectively.
In Parts Registry, there are composite parts, translation units, generators, reporters, inverters, intermediate devices, and signaling devices. As Parts Registry 2011 distribution was being examined in detail, to simplify these parts, their connection information was simplified to promoter-ribosome binding site-gene-terminator relation by our biological knowledge. This rule is explained with details as seen below:
- Reporters
The biobricks which synthesize fluorescent proteins are classified as “reporters” as they give out light to report something. We accepted these parts as “genes” because they are synthesizing proteins.
- Translational Units
Combination of ribosome binding site and gene is classified as “translational units”. We accepted this as two biobricks rather than one. Therefore the bilateral relation between ribosome binding site and gene was entered in our database.
- Inverters
Inverters were challenging parts; they are formed from more than 2 biobricks. Rather than accepting this as one biobrick, we accepted this part as a combination of four biobricks. Therefore, we entered bilateral relations between each biobricks as ribosome binding site-gene, gene-terminator, and terminator- promoter. We also entered gene-output and input-promoter connections.
- Composites
- Genereators
- Signalling Devices
- Intermediate Devices
Composite parts, generators, signaling devices, and intermediate devices were also challenging parts like inverters. They don’t have a specific rule about how many and which types of biobricks they consist of. However, we accepted them as complex subdevices and entered bilateral relation between each connected biobricks.
In METU-BIN 2011 project, our main priority was to focus on (minimal) Functional devices. Therefore we named DNAs, RNAs, and Tags as “accessories” because they are not vital for a device to work. However, we know that using these accessories during construction helps devices work more effectively by adding some extra features. For that reason, it’s in on future plan to form a database for these accessories and present them to our users in their query results.
Scoring
Results
See our software, it's online!
Find us on




Some photos during work